In my second stint at ThoughtWorks I spent a little over a year working on their Continuous Delivery tool GoCD, now Open Source!. Most of the time working with customers was more about helping them understand and adopt Continuous Delivery rather than the tool itself (as it should be).
The most common remark I got though was “Jenkins does CD pipelines too” and my reply would invariably be “on the surface, but they are not a first class built-in concept” and a blank stare usually followed 🙂
I use Jenkins as an example since it’s the most widespread CI tool but this is really just an excuse to talk about concepts central to Continuous Delivery regardless of tools.
It’s often hard to get the message across because it assumes people are comfortable with at least 3 concepts:
WHAT PIPELINES REALLY ARE AND WHY THEY ARE KEY TO A SUCCESSFUL CD INITIATIVE
THE POWER OF THE RIGHT ABSTRACTIONS
WHAT FIRST CLASS BUILT-IN CONCEPT MEANS AND WHY IT’S KEY
What CD and Pipelines are
I’ll assume everyone agrees with the definitions Martin posted on his site. If you haven’t seen them yet here they are: Continuous Delivery and (Deployment) Pipelines. In particular on Deployment Pipelines he writes (emphasis mine):
“A deployment pipeline is a way to deal with this by breaking up your build into stages […] to detect any changes that will lead to problems in production. These can include performance, security, or usability issues […] should enable collaboration between the various groups involved in delivering software and provide everyone visibility about the flow of changes in the system, together with a thorough audit trail.”
If you prefer I can categorically say what a pipeline is NOT: just a graphic doodle.
Why Pipelines are important to a successful CD initiative
Since Continuous Integration (CI) mainly focuses on development teams and much of the waste in releasing software comes from its progress through testing and operations, CD is all about:
much of the waste in releasing software comes from its progress through testing and operations
- Finding and removing bottlenecks, often by breaking the sequential nature of the cycle. No inflexible monolithic scripts, no slow sequential testing, no flat and simplistic workflows, no single tool to rule them all
- Relentless automation, eliminating dull work and the waste of human error, shortening feedback loops and ensuring repeatability. When you do fail (and you will) the repeatable nature of automated tasks allows you to easily track down the problem
- Optimising & Visualising, making people from different parts of the organisation Collaborate on bringing value (the software) to the users (production) as quickly and reliably as possible
scripting and automated testing are mostly localised activities that often create local maxima with manual gatekeepers
Commitment to automation is not enough: scripting and automated testing are mostly localised activities that often create local maxima with manual gatekeepers – the infamous “throwing over the wall” – to the detriment of the end-to-end value creating process resulting in wasted time and longer cycle-times.
GoCD Pipelines vs Jenkins Pipelines
Jenkins and GoCD Pipelines are so hard to compare because their premises are completely different: Jenkins pipelines are somewhat simplistic and comparing the respective visualisations is in fact misleading (Jenkins top, GoCD bottom): 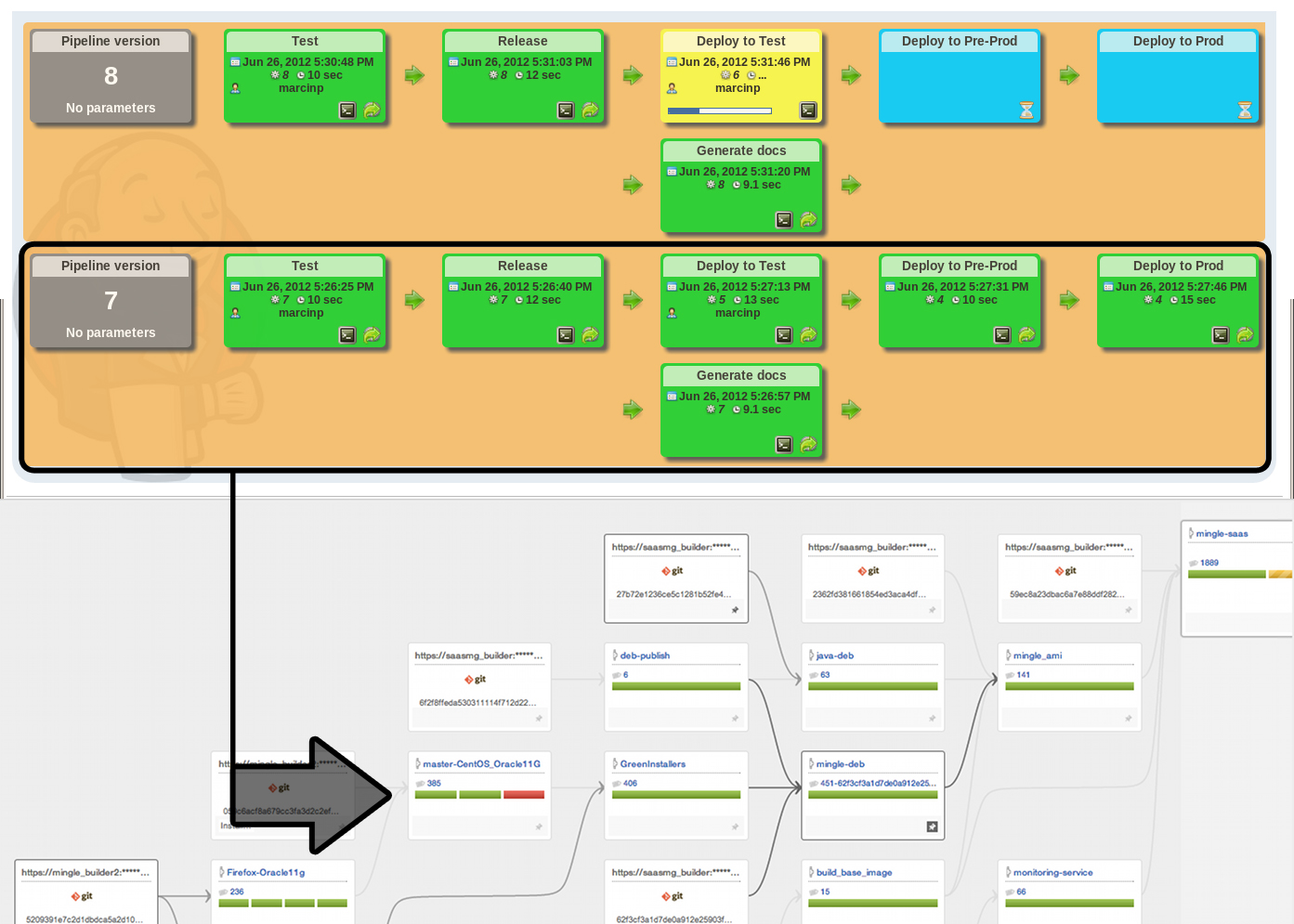 If there are only two of things you take away from this post let them be these:
If there are only two of things you take away from this post let them be these:
- An entire row of boxes you see in the Jenkins visualisation is a pipeline as per the original definition in the book (that Jez Humble now kind of regrets :-)) each box you see in the Jenkins pipeline is the equivalent of a single Task in GoCD
- in GoCD each box you see is an entire pipeline in itself that usually is chained to other pipelines both upstream and downstream. Furthermore each can contain multiple Stages that can contain multiple Jobs which in turn can contain multiple Tasks
I hear you: “ok, cool but why is this significant?” and this is where it’s important to understand…
The power of (the right) abstractions
You might have seen this diagram already in the GoCD documentation: 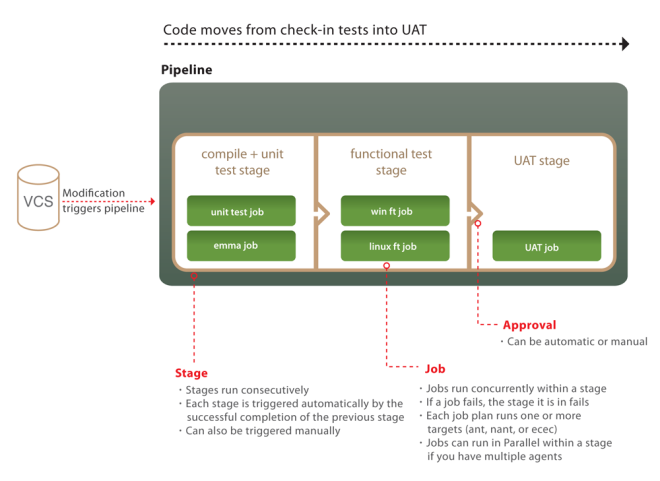 Although it really is a simplification (here a more accurate but detail-dense one), it tries to convey visually 2 very important and often misunderstood/ignored characteristics of GoCD:
Although it really is a simplification (here a more accurate but detail-dense one), it tries to convey visually 2 very important and often misunderstood/ignored characteristics of GoCD:
- its 4 built-in powerful abstractions and their relationship: Tasks inside Jobs inside Stages inside Pipelines
- the fact that some are executed in parallel (depending on agents availability) while others sequentially:
- Multiple Pipelines run in parallel
- Multiple Stages within a Pipeline run sequentially
- Multiple Jobs within a Stage run in parallel
- Multiple Tasks within a Job run sequentially
Without geeking out into Barbara Liskov’s “The Power of Abstraction”-level of details we can say that a good design is one that finds powerful yet simple abstractions, making a complex problem tractable.
a good design is one that finds powerful yet simple abstractions, making a complex problem tractable
Indeed that’s what a tool that strives to support you in your CD journey should do (because the journey is yours and a tool can only help or get in the way, either way it won’t transform you magically overnight): make your complex and often overcomplicated path from check-in to production tractable. At the same time “all non-trivial abstractions, to some degree, are leaky” as Joel Spolsky so simply put it in “The Law of Leaky Abstractions” therefore the tricky balance to achieve here is:
“to have powerful enough abstractions (the right ones) to make it possible to model your path to production effectively and, importantly, remodel it as you learn and evolve it over time while, at the same time, resist the temptation to continuously introduce new, unnecessary abstractions that are only going to make things more difficult in the long run because they will be leaky”
And of course we believed (and I still do) we struck the right balance since we’ve been exploring, practicing and evolving the practice of Continuous Delivery from before its formal definition.
you are supposed to model your end to end Value Stream Map connecting multiple pipelines
This is the reason why you are supposed to model your end to end Value Stream Map connecting multiple pipelines together in both direction – upstream and downstream – while everyone seems to still be stuck at the definition by the book that (seems to) indicate you should have one single, fat pipeline that covers the entire flow. To some extent this could be easily brushed off as just semantics but it makes a real difference when it’s not about visual doodles but about real life. It may appear overkill to have four levels of abstraction for work execution but the moment you start doing more than single team Continuous Integration (CI), they become indispensable.
Jobs and Stages are primitives, they can and should be extended to achieve higher order abstractions
For instance, it is trivial in GoCD to set up an integration pipeline that feeds off multiple upstream component pipelines and also feeds off an integration test repository. It is also easy to define different triggering behaviours for Pipelines and Stages: if we had only two abstractions, say Jobs and Stages, they’d be overloaded with different behaviour configurations for different contexts. Jobs and Stages are primitives, they can and should be extended to achieve higher order abstractions. By doing so, we avoid primitive obsession at an architectural level. Also note that the alternating execution behaviour of the four abstractions (parallel, sequential, parallel, sequential) is designed deliberately so that you have the ability to parallelise and sequentialise your work as needed at two different levels of granularity.
What First Class Built-in Concept means
In order for Pipelines to be considered true first class built-in concepts rather than merely visual doodles it must be possible to:
- Trigger a Pipeline as a unit
- Make one Pipeline depend on another
- Make artifacts flow through Pipelines
- Have access control at the level of a Pipeline
- Associate Pipelines to environments
- Compare changes between two instances of a Pipeline
Not all Pipelines are created equal, let’s see why the above points are important by looking at how they are linked to the CD best practices.
| CD Best Practices (from the CD book) | First Class Built-in Concepts |
| Only build your binary once | Pipeline support for: dependency and Fetch Artifact |
| Deploy same way to every environment | Pipeline support for: Environments, Templates, Parameters |
| Each Change should propagate instantly | Pipeline support for: SCM Poll, Post Commit, multi instance pipeline runs |
| If any part fails – stop the line | Basic Pipeline modeling & Lock Pipelines |
| Deploy into production | Manual pipelines, Authorization, Stage approvals |
| Traceability from Binaries to Version Control | Compare pipeline + Pipeline Labels |
| Provide fast and useful feedback | Pipeline Visualization + VSM + Compare pipelines |
| Do not check-in binaries into version control | Recreate using Trigger with options |
| Model your release process | Value Stream Maps |
| Support Component and Dependency Graph | Pipeline Dependency Graphs and Fanin |
Fan-in
Last but not least Pipelines as first class built-in concepts are part of the reason why we were able to release the first ever (and at the moment still only, AFAIK) intelligent dependency management to automatically address the Dreaded Diamond Dependency problem and avoid wasted builds, inconsistent results, incorrect feedback, and running code with the wrong tests: in GoCD we called it Fan-in Dependency Management. GoCD’s Fan-in material resolution ensures that a pipeline triggers only when all its upstream pipelines have triggered off the same version of an ancestor pipeline or material. This will be the case when you have multiple components building in separate pipelines which all have the same ancestor and you want downstream pipelines to all use the same version of the artifact from the ancestor pipeline.
Further reading
If you haven’t read the Continuous Delivery book you should but chapter 5 ‘Anatomy of the Deployment Pipeline’ is available for free, get it now. Time ago a concise but exhaustive 5-part series on “How do I do CD with Go?” was published on Studios blog and I still highly recommended it:
- Domain model, concepts & abstractions
- Pipelines and value streams
- Traceability with upstream pipeline labeling
- GoCD environments
- The power of pipeline templates and parameters
and last but not least take a look at how a Value Stream Map visualisation helps the Mingle team day in, day out in Tracing our path to production.
P.S.: yes, Jenkins is getting better
April 2015 Update
Despite being almost a year old this post still gets lots of viewings every single day. For an update on the latest relevant plugins in the Jenkins space take a look at Max Griffiths article Go CD – The right tool for the job?